Release Notes: Version 24.01
New Features
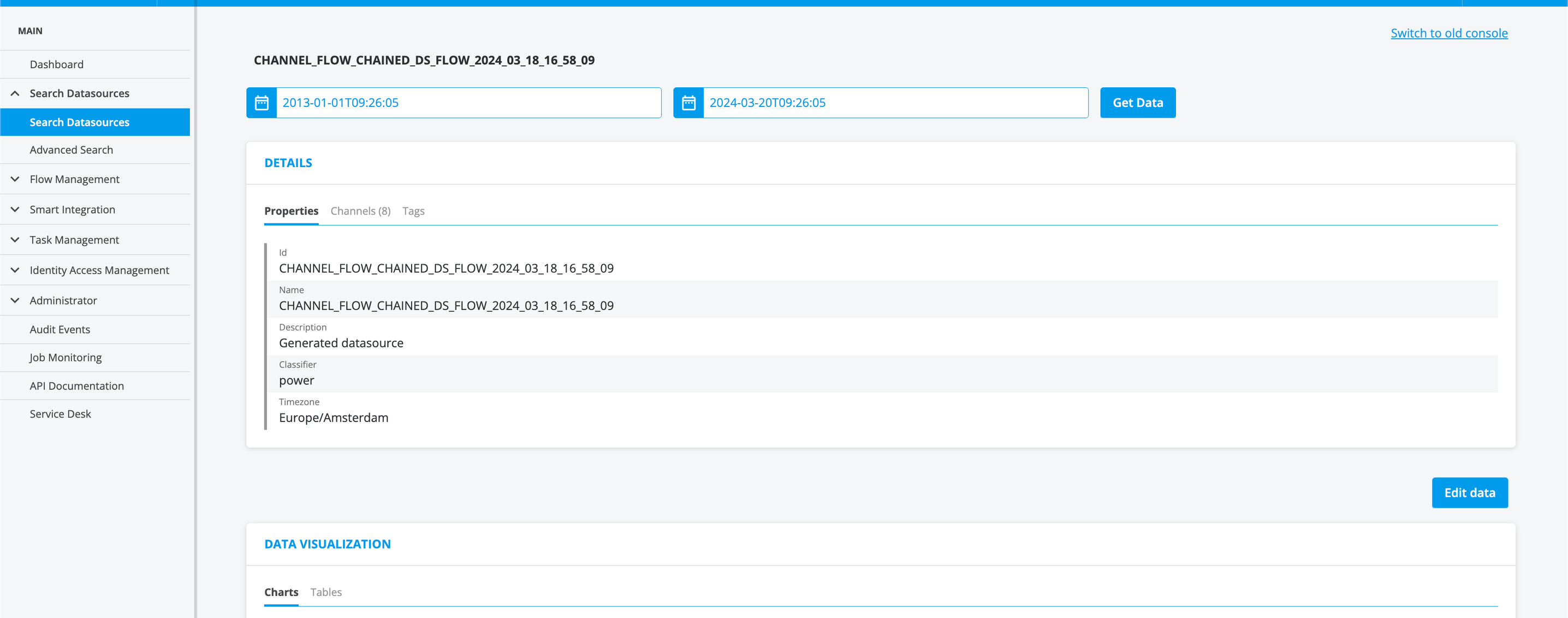
Console - New Datasource View 🎉
We're excited to introduce our newly designed datasource view, engineered from scratch with a strong emphasis on usability, performance, and streamlined processes. This beta version introduces core functionalities including the ability to view, edit, and export timeseries, datapoint attributes, and annotations, as well as exposing datasource properties and tags view to the new API, ensuring a focus on essential components for a more efficient user experience. Additionally, the channels classifier view is now available for beta testing. Activate these beta features through your user settings on an opt-in basis; deployment and configuration is required on a project basis.
Key Updates Include:
- User Interaction Enhancements (EWXDEV-837) : Select and inspect datapoint attributes and annotations directly by clicking on a timeseries datapoint for an intuitive analysis experience.
- Multilingual Support (EWXDEV-5986) : Enjoy a consistent user experience across multiple languages, leveraging shared translations from the existing views and console.
- Improved Tag Visualization (EWXDEV-6840, EWXDEV-6842) : Experience an enhanced viewing of tags with increased real estate and a new tag component in our style guide. Users can view future tags as well as removed tags. Tags are available in the new datasource view
- Editable Timeseries (EWXDEV-8559) : Users can now edit timeseries, datapoint attributes, and annotations with a mandatory edit reason, currently available for continuous flows only.
- Clickable annotations and attributes in Datasource Details (EWXDEV-837) : The new datasource view allows users to inspect the Datapoint Attributes and Annotations by clicking on the timeseries datapoint, users can visualise Datapoint Attributes and annotations while timeseries is hidden
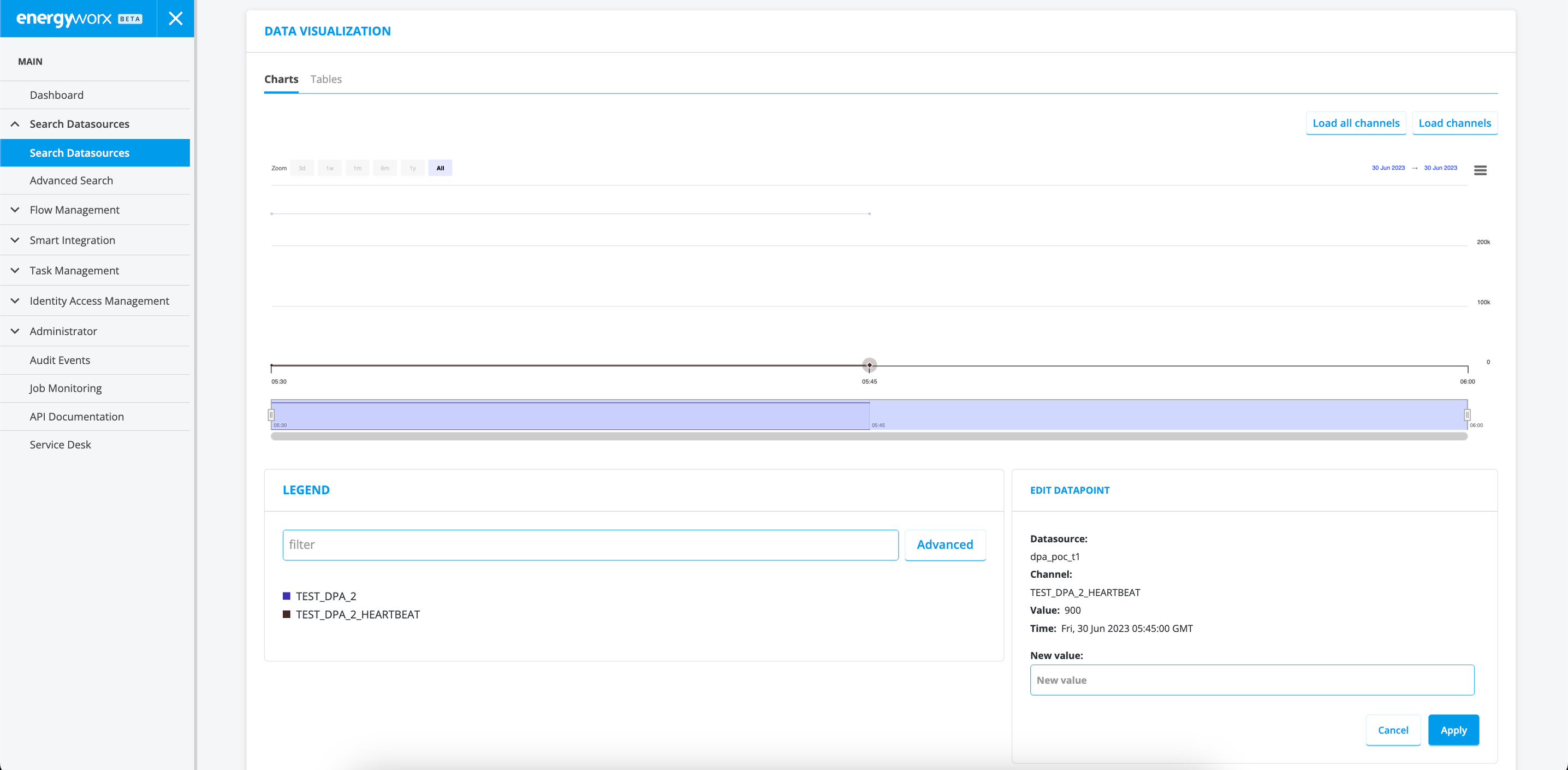
Please note, this beta view does not yet offer full feature parity with the existing view and is continuously being improved based on your feedback.
Customers may notice a refreshed appearance in data representation. This change is due to the implementation of dynamic scaling in our new console's graphs, which adjusts based on data availability to optimise viewing. This may result in different looking charts even when the data is identical
If you have any feedback for us on this view, please share it through this portal: Feedback Collection Portal
To go with the new Datasource View, we’re also introducing a new API. We’ve rewritten this API using the newest technologies and conventions resulting in a number of improvements including, importantly, speed. The new API is in beta with the corresponding new console view and is being continuously improved with additional features being added to match the offering of the ‘old’ API.
Key Aspects of the API are currently:
- Datasource Functionality (EWXDEV-5857,EWXDEV-8198): Endpoints to query and perform writing/editing on timeseries data.
- Datasource and Channel Classifier Functionality (EWXDEV-5857,EWXDEV-8560): Endpoints to query and perform writing/editing on timeseries data. This also includes the new Datapoint Attributes functionality for usage with the Channel Classifiers.
- Tag Functionality (EWXDEV-8198,EWXDEV-6840): Endpoints to query and perform writing/editing on tag data related to a datasource.
- Timeseries Functionality (EWXDEV-5857,EWXDEV-8559): Endpoints to query and perform writing/editing on timeseries data. This also includes the new Datapoint Attributes functionality.
EWXDEV-7326 Console - Edit datapoint function displays who made a change
Users are able to view edited datapoint with labels on the user and date of edit in Datasource view, both in the chart and table
EWXDEV-8340 Console - Limited support for Virtual Datasources interaction buttons
In order to create a virtual datasource, it is necessary to create using the virtualdatasource/create endpoint and trigger it. This can be achieved either using the endpoint virtualdatasource/trigger or sending the triggerNow option during the creation.
Please Note: the trigger button (or virtualdatasource/trigger endpoint) is not working for the existing (before this release) Virtual Datasources at this moment.
EWXDEV-3006 Access Management - SAML Integration
Single sign-in with SAML support. Users can log in in the energyworx platform by using their existing user account on other systems (support only for Microsoft and Google accounts).
This is supported through domain white-listing, meaning that all users belonging to a domain that is white-listed in the platform will be logged in automatically.
Automatic group-mapping is also provided. This enables the user to be assigned automatically upon log in to a group in the platform. This group can also be mapped to a specific group on the customer's own authorization system.
EWXDEV-6785 Flows - Support Chain flow(s) on Virtual Datasources result
It is now possible to add a flow configuration ID for the vds_aggregation_ingest trigger schedule. This flow that will be executed on the resulting Virtual Datasources and will be triggered after a delay of one hour, to ensure that the data is in BigTable before the flow is executed.
EWXDEV-9334 New Channel Classifiers' Units
It's now possible to create Channel Classifiers with datasource type “Signal” and new unit types: dB, dBm, Hz and Electric Current
EWXDEV-8207 Rules Framework - New load timeseries service
Introduced the new 'TimeseriesService'; the replacement for 'AbstractRule.load_side_input' and 'AbstractRule.load_timeseries'.
⚠️ WARNING: With this change, the following methods in 'AbstractRule' are deprecated and will be removed in 24.04:
'load_side_input'
'load_timeseries'
'add_side_input_requirement'
Using any of these methods in 24.01 will create a deprecation warning audit event the first time they are used within each unique flow.
With 24.04, all rules that still use any of these methods will no longer function and need to be refactored!
EWXDEV-9097 Rules Framework - Deprecation of send_bulk_trigger
The 'AbstractRule.send_bulk_trigger' method has been removed. Use the 'AbstractRule.send_collective_trigger' method instead.
EWXDEV-8981 Under the Hood - Move APIv1.5 to new k8s cluster
Infrastructure change: The lionshare of the api endpoints will no longer be served from Google App Engine (GAE) but from a Kubernetes service running in GKE.
The API endpoint is now ah.<gcp_project>.ewxapis.com instead of api.<shortened_gcp_project>.energyworx.org
Energyworx will schedule a session with you to cover the following implications of this more cost-efficient setup:
Nonstandard networking on production environments could be affected - This needs a session with the integrator to verify any breaking changes.
As scaling has always been done for us in GAE, this will mean that for each project we will need to find the right setting with this new k8s implementation.
EWXDEV-9359 Under the Hood -Performance improvements on how the timeseries data is written in our GCP databases.
EWXDEV-9376: CLI's 'config download' command ('Manager.to_dir') can now properly deal with merging configs into a directory with downloaded configs.
EWXDEV-9562: Added support for decompressing writer messages in cloud storage writer
EWXDEV-8717 Automated Testing Framework - Replace configuration/authentication management in pytest-bdd-ewx with resource manager from ewx-cli
Replaced the authentication services in pytest-bdd-ewx with the one from ewx-cli for APIv1:
This means that authentication locally can now be done without using environment variables and with the automated authentication that ewx-cli users are used to.
Any missing environment variables are now simply requested from the user to be provided from the command-line.
Namespace aliases can be provided as target namespaces as well.
Due to using the ewx-cli automated authentication, automated tests ran are now also marked as having been ran by the actual user instead of a default testing user, improving traceability and reducing security issues.
The configuration manager of ewx-cli can now be used within pytest-bdd-ewx
Configurations directories created with 'ewx-cli config download' can now be treated as proper configurations within pytest-bdd-ewx.
Several new step definitions were added where an automated test can initialize a resource manager from a configurations' directory. Users can both create a default resource manager available to all automated tests or a named resource manager only available to the automated test that initialized it. A step definition was also introduced that allows an automated test to upload all configurations available in a resource manager.
Many new step definitions were added for all supported resource types where the user can request from either the default or a named resource manager to upload a specific resource type with a specific name. This will upload that resource configurations plus any dependencies it may have, similar to the effect you normally get with 'ewx-cli config upload'. Step definitions also exist where a regex pattern can be provided that names of that resource type must satisfy, or when the user wants to upload all configurations of that resource type.
$-substitution is still fully supported. If a value in a configuration in a configurations directory has the substring {$test_timestamp}, then that will be replaced by the actual testing timestamp.
The old fashion way of writing automated tests is still supported, but it is recommended to start using the new step definitions with the ewx-cli's resource manager, as it is far more efficient and reduces the complexity of automated test suites.
New Fixes
- When a new data is ingested for a datasource, the (previous) annotations are now correctly overwritten.
- Ingesting timeseries data that is not a float will now properly raise an error. Example: "Channel(s) TEST failed to transform for datasource(s): XXX, with message: One or more values in channel data cannot be converted to float"
sourceClassifierattribute needs to be a valid channel classifier in order to run a flow, if not it will result in an error and the flow will not be executed.
IfsourceClassifieris not given it will use the source channel of the flow configuration id- Fixed a small issue to ensure consistency between the default selected namespace on the new datasource view
- Fixed an issue on dashboards where chart widgets were empty on first load, or the legend section was shown as empty
- Dashboard table columns resizing to fit the data
- Fixed a bug where file tags where disappearing after ingestion
- Fixed an issue where Datapoint Attributes retrieved wasn't returned always in the same order from the APIv2
- Added audit event to specify which rule failed during prepare context. This way the user has a better understanding of which point in the flow there was an error.
- Fixed an issue where a flow failed if you assigned a task board in the task configuration.
- Fixed Redis IP being set incorrectly.
- Configured task board assigned to tasks created from flows
- In some cases, a Bigtable DeadlineExceeded error would end up in an audit event instead of being retried.
- Fixed an issue where users couldn't select a subset of the flows after editing datapoints
- Fix for errors querying FlowMetaData for specific datasources via API which do not have the readOnly flag set.
- Fixed the create/patch Channel Family endpoints
- Fixed loading of transformation configurations in API v1.5
- Make sure that timeseries retrieval is end-inclusive.
- Fix for flows not starting.
- Fixed an issue that prevented some specific filter combination for searching in File Management and Task Management.
- Fix task schemas in API v1.5
- Fix to use the default appengine service account for the python3 API service.
- Fixed issue with flows not loading.
- Fix flow start from task page
- Fix task filtering using statuses for API v1.5
- Task Boards are fixed and can now be updated.
- Always drop the version index label for the channel source data.
- Fixes issue with loading transformation configurations in the console.
- Fixed time formating to %Y-%m-%dT%H:%M:%S.%f matching what's used in production.
- Pass the data to the correct parameters and correctly format it
- Aligned the names for the task creation attributes.
- Split channel classifier and timeseries GET requests on the datasource detail page to prevent query parameter overloads.
- Fixed loading of tasks on the task flows endpoint.
- Make sure that nested rules can also be loaded directly.
- Fixed proper parsing of annotation fields in the streaming ingest
- Annotations are now added with their full name to self.dataframe
- Fixed issue with APIv1.5 for the file content endpoint.
- Fixed issue in creating legacy Virtual Datasources
- Table height adjustments ensure consistent display, regardless of row quantity.
- Datapoint Attributes should now no longer be visible in the frontend as unreadable byte values.
- Fixed issue with annotations not showing in the frontend console timeseries chart.
- Channels tab doesn't trigger datasource flows now
- Fixed an issue where users couldn't access Triggers that they were authorised for it
- Fixed an issue where conditionally chaining datasource flows still required a classifier
- Added standard utils back
- Fixed an issue where the defer-task-queue got paused after app engine was deployed.
- Resolved: Conditional flow rule inputs now fully editable, including setting Start Delay in chain flows.
- Fix issue of the store rule not storing Datapoint Attributes if the value of the Datapoint was set to NaN or None.
- Datastore timeouts in Streaming-Ingest no longer result in silent errors and will instead be retried by Pub/Sub.
- Added hotfix for the usage of dictionaries in annotations.
- Fixed an issue where the annotation used for creating tasks from a flow would affect the startDate subject of the task.
- Fix annotation editing via the console.
- Fixed a CORS issue that affected the smooth transition between the new datasource view and the existing view
- Solve the issue of potentially invalid cached model id
- Annotation and datapoint editing has been fixed to work for the same timestamp.
- Fixed Tags with Timestamp properties showing the property in the UTC timezone instead of the Datasource timezone.
- Fixed an issue where Timeseries could not be retrieved if a specific Service Account was not whitelisted to the namespace.
- Fixed API key usage for API v1.5
- File details now has a functional download link when clicking the file name.
- Front-end console adjustment so text isn't shown twice for datasource.
- Fixed a login issue that affected users that had not been registered in the platform yet.
- Fix for a bug where task search didn't work if there is no one assigned.
- Fixed bug preventing annotation/datapoint edits from being reflected in the chart prior to the edit going through.
- Fixed timestamp inconsistency in datasource properties where an edited datapoint's timestamp would always be displayed in UTC even when the user has selected another timezone (such as Europe/Amsterdam).
- Ensure that Tag objects are always created with lowercase names.
- duplication of the Virtual Datasources filter property fixed from frontend side with a limitation that it's not possible currently to edit it from UI. The root cause still should be fixed on the backend (as part of another ticket)
- Fixed datapoint editing timezones
- Modified bulk_chain_flow to accept datasource flows without a target channel classifier
- Fixed an issue where switching between visualisation types didn't apply to the chart
- Fixed issue that prevented the IAM Group create and update endpoints from showing up in API docs.
- Task descriptions originated from detector elements in flows will be limited to less than 1500 characters to prevent excessive storage use. Detectors information is already available in the flow metadata if needed.
- Fixed issue where searching for files was very slow for retrieving a large amount of files.
- Timeseries values that have been written with datapoint attributes can now be viewed in the console using APIv1.5 (without the datapoint attributes themselves). For retrieval of datapoint attributes, please use APIv2
- Added functionality for Collective Trigger to trigger single message after deadline has reached. This means that when this option is chosen every message that arrives after the deadline will trigger a flow with only the flow properties of this single message. The function
send_collective_triggerhas been modified to support this. - Fixed a bug where Datapoint Attributes were not stored correctly in BigTable when the dataframe did not include the channel classifier, but did include the Datapoint Attributes.
- Fixed a bug where datapoint attribute columns were treated as channels, causing the serialization of the data to fail.
- Added workaround that removes duplicate timestamps that have the same version as well.
- All timeseries functions that retrieve existing data correctly processes Datapoint Attributes values
- Extend signedURL on API file manager model to work beyond 1500 bytes.
- Make sure that any channels created during 'apply' for a Datasource are also added directly to the Datasource to allow channel flows to be chained to them.
- Use pickle's protocol-2 for any trigger send out from streaming-ingest to allow Python 2.7 services to pick up such triggers appropriately.
- heartbeat channels are ignored for timeseries reading in APIv2
- Fixed issue where the billing account cannot be saved if no email domains are set.
- Fixed bug with triggers starting task archiving.
- Fixed dashboard charts to have proper legends with channel names.
- Added Datapoint Attributes to the datasource console page and added Datapoint Attributes editing functionality.
- Datapoint attributes can now be stored with values like float.NaN, np.nan, pd.NA and None. Those values will be filtered and will not be saved.
- Make sure to only store the latest version of each datapoint that has been marked for storage in the flow.
Impact Analysis
Trigger Aggregation Deprecation Notice
From release 24.01, we will remove the send_bulk_trigger function from the rule framework, for message orchestrating, we recommend using the send_collective_trigger function instead.
Package Deprecation Notice
Starting February 2024, the existing ewx client python package that used APIv1 to connect to Energyworx API will stop receiving stability updates and will eventually be phased out, in favour of supporting the generation of new API clients based on our Partner's preferred language.
Please contact Energyworx support for assistance when deploying regarding these actions
Shutdown of GAE py3 API
We’re moving APIv1.5 to Kubernetes. This will be deployed automatically. However, two manual things need to happen:
- Old load balancer needs to be updated to route traffic to the Kubernetes service.
- Remove the GAE py3 service after deployment. So that no traffic can accidentally use the old service.
Cleanup App Engine execute_triggers
The execute_triggers has been moved to a terraform managed "Cloud Scheduler Job". It used to be a Google AppEngine's “Cron Job”. The old job gets now orphaned after deletion of the GAE service. It needs need to be cleaned up manually.
Re-index Datasources for Search functionality.
This release removes the default Kubernetes cluster used in the previous release and recreates it (ewx-unicorn). This thus deletes the ElasticSearch cluster and any data in it. This needs to be re-indexed.
Changelog
24.01 hotfix 1
- Big improvement to the datasource view speed. Mainly when timeseries and flow metadata is being retrieved.
- New Datasource View: Fixed an issue where source channels could be edited.
- New Datasource View: Added
removedandcreated byfields to tags. - Datasource View: Fixes an issue when searching legends by channel name.
- Increased the number of data queried on a datasource which allows large datasources to be loaded robustly
- Fixed an issue where timeseries wasn't visible in the platform when it contained empty timestamp values
- Fixed an issue of missing references for building configuration outside the platform
24.01 hotfix 2
- Fixed an issue where blacklisted channels were not hidden in the new datasource view
- Added better exception handling for retryable errors in the decision tree execution.
- Flow properties for collective trigger now accept any type that is serialisable in python (with pickle)
- Validation logs in audit events now shows serialised timeseries data for each Channel Classifier in case of failure.
- Fixed a security issue with group permissions where blacklist conditions using datasources and tags weren't enforced
- Fixed an issue where the link to the energworx Service Desk in the Console was not working
- Fixed a pagination issue across refreshes on the new datasource view
- Providing an edit reason is now mandatory from new datasource view when editing a datapoint
- Long names are now truncated in the top bar breadcrumbs
- Unit types and intervals should be part of the channel classifier in the new Datasource View
- Fixed an issue in the new Datasource View where the tags version timelines wasn't responsive to the screen size
- In the new Datasource View, fixed an issue where showing removed tags filtered non-removed tags
- In the new Datasource View, channels are loaded automatically when “Get Data” is selected.
- In the new Datasource View, a datasource timezone is respected in the chart, table and tags properties
- In the new Datasource View, it's not allowed to edit source channels timeseries data
- In the new views, the namespace label is shown under the username in the top right of the screen
24.01 hotfix 3
- Fixed an issue where Channel name from Channel Classifier was not provided, now it's working when Channel name was empty or None value by showing the Classifier's technical name.
- Fixed an issue where navigating between the current and experimental console view caused excessive numbers of requests.
- Channel Family can now be chosen using the API.
- Fixed an issue on the new datasource view where a new token was being requested for every API call.
- Fixed an issue where blacklisted channels were still shown in the datasource view.
- Corrected the assignment of roles and permissions in the identity service.
- Under the hood - Removed AppEngine Cron Jobs that caused trigger schedules to run in duplicate.
- Fixed an issue with channel classifier caching in the new datasource view wasn't utilised.
- Under the hood - Unified serialisation package use in the platform code.
24.01 hotfix 4
- Fixed an issue in the new datasource view where the API's token refresh was called more time than necessary
- Fixed an issue when updating channel classifiers affected the channel classifier count
- Corrected issue such that APIv2 always loads the latest datasource version.
- Fixed issue where edits with the word
_nan_in them were not displayed via the api.
24.01 hotfix 5
- Fixed issue where group permission properties could not be altered and fetch via apiv1.5.
- Added support for api_key_allowed for retrieving datasources via
datasource/get/{id}route - Datapoint Attributes interpret 0 value correctly as a number instead of
Nonevalue - Fixed an issue where
load_side_inputmethod in Rules Framework still use cache even when bypass_cache flag was set to True - Fixed an issue where datapoint edits didn't behave consistently in APIv1.5 across different data structures when deserialising
- Fixed an issue where datapoint edits didn't show correctly in APIv1.5 and APIv2
- Under the hood: more robust writers quota
24.01 hotfix 6
- Changed the parameter page size to load full versions of Tags in apiv2.
- In certain scenarios where Market Adapters require context data (e.g. ancillary datasources like a Meter for a Metering Point) the context data was too large, reaching the limits of the queueing system in between the pipelines of the platform. To solve this we applied compression on the exchanged messages in the queuing system.
- Fixed an issue where edits with zero-values did not persist in the table in the new datasource view.
24.01 hotfix 7
- Fixed an issue with editing Datapoint Attributes via frontend where cells belonging to any channel could be edited for a row belonging to a different channel.
24.01 hotfix 8
- Fixed an issue with ‘Abort on Error’ feature in Flows. If the error threshold is reached, a task will be created and flow execution will stop. Please note: All the data that was saved until that point will be persisted.
- It is now possible to add data from other datasources to self.dataframe when using store_timeseries.
- Fixed an issue when editing Datapoint Attributes and annotations on the same datapoint on the console in datasource view.
- Under the hood: It's possible to support push subscription for external components outside the platform
- Fixed an issue where the validation of the Datapoint Attributes data type didn't raise an error. It now causes the flow to stop executing with a suitable error message in the audit events.
- Added better logging in audit events when the market adapter fails to parse the data provided into energyworx domain objects.
- Cloud log error message when logging DeadlineExceeded error is more descriptive
- Datasource view in the console shows dates in Datapoint Attributes values parsed correctly
- New API Documentation URL is updated correctly to match the standard convention
- We've simplified the file management search by cleaning up the read-only/writeable filters.
- Under the hood: Channel classifiers are better cached in the processing pipeline for faster storage of Datapoint Attributes.
24.01 hotfix 9
Infrastructure & Performance
- Under the hood - Updated deployment software for improved reliability
- Fixed an issue where AH pods were entering restart loops due to probe settings
- Entity writer now uses transactional commits for improved reliability
Data Processing & Rules Framework
- Messages in processing pipelines now include message IDs to prevent duplicate triggering
- File creation from flows is more robust, addressing issues with dead-letter queues
- Fixed precision of version_ts field in BigQuery tables for edited datapoints to maintain millisecond accuracy
- Rule Framework - Enhanced handling of empty datapoint values in dataframes
- Processing pipeline now continues to handle Datapoint attributes even when Datapoint values are empty
- Chain rules (bulk, condition, chain) enhancement:
- Added new start_datetime and end_datetime parameters
- If not specified, the triggered flow will use either:
- Dataframe indexes (if available)
- Last two years (as default fallback)
- Data processing improvement: Rule parameters of type timestamp now default to datasource timezone instead of New York timezone
User Interface & Experience
- Dashboard Widget QuickSetting - Improved field sizing for better user input experience
- Advanced search functionality now consistently supports double quotes in queries across API usage
- Simplified file management search by removing read-only/writeable filters
- UI improvements:
- Fixed "No results found" message display when filtering channels in legend
- Tag properties with timestamp type now display with correct timezone in edit mode
- Load channels button is properly disabled when all channels are loaded
Logging & Monitoring
- Added more detailed audit event logging for SOAP file uploads to show filename
24.01 hotfix 10
Stability & Performance Improvement
We resolved an issue that affected resilience in the cloud-notification-router workload, the impact affected 1 in 5 million processes, and resulted in the data not being stored