Understanding Our Platform's Core Kubernetes Workloads
Our cloud-based energy data platform uses Kubernetes to efficiently manage and process your valuable energy data. Kubernetes helps us organize and scale our services reliably, ensuring your data is ingested, transformed, and made available for insights seamlessly.
Each key operation within our platform is handled by a dedicated Kubernetes workload. These workloads typically process messages from Pub/Sub subscriptions , which act as data queues. These messages contain the relevant data, sent either by our platform's APIs or by external systems.
Below, we'll explain the primary workloads that power our platform, categorized by their main function.
Understanding the Naming Convention
You'll notice consistent naming patterns like a process pool suffix and resource-specific prefixes. Let's break them down:
- Resource-Specific Writers (e.g.,datasource-sink-bigtable-1,timeseries-sink-bigtable-1) : These writer workloads are specialized based on the specific type of data or "resource" they are handling:
- datasource-sink-bigtable-1 : Messages for this writer are consumed by the workload that writes datasource data into Bigtable.
- timeseries-sink-bigtable-1 : Messages for this writer are consumed by the workload that focuses on writing your time-series data (e.g., energy consumption readings over time) to Bigtable.
- Process Pool Suffix (e.g., -1, -pool-a) : The suffix signifies the Process Pool for which these resources are associated. Process pools separate data processing into different compute environments. Our platform allows users to have multiple namespaces within a single project, and these namespaces can be linked to different process pools. This design ensures resource isolation for the various namespaces within a project. Each process pool has an ID (which can be any alphanumeric string) and this is the one that you will see in the real subscriptions in your specific projects.
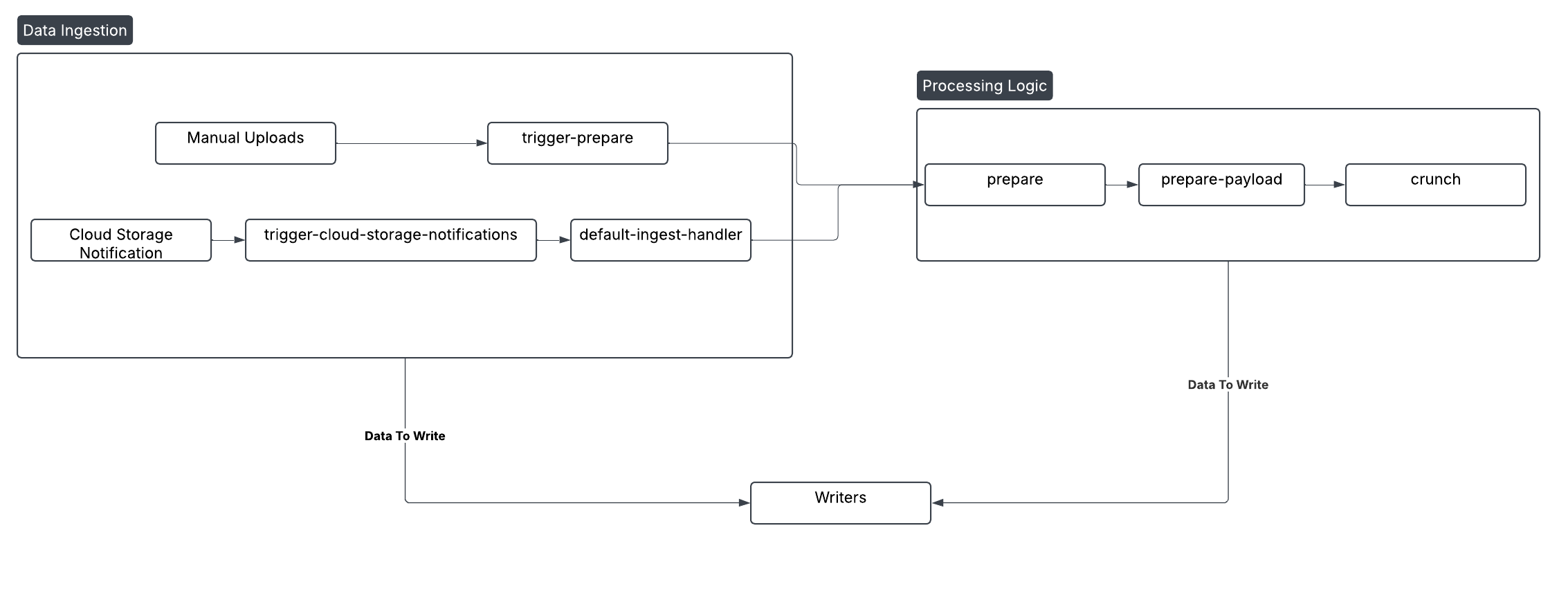
Processing Workloads: Ingestion, Preparation, and Processing Logic
These workloads form the backbone of our data pipeline. They're responsible for bringing your data into the system, preparing it, and applying core business logic. Designed for continuous operation and high throughput, they consume various data streams and messages. Some of the pubsub subscriptions these workloads listen to, are:
- trigger-cloud-storage-notifications : Messages sent to this Pub/Sub subscription are consumed by a processing workload. Its job is to notify when a new file has been added to Google Cloud Storage (GCS) and then trigger the appropriate ingestion process.
- default-ingest-handler : This workload consumes messages for automatically ingested files. Whether your energy data streams from smart meters, IoT devices, or other automated sources, this handler ensures it enters our system efficiently.
- trigger-prepare-{pool} : This workload consumes messages specifically for manually uploaded files. It applies a similar logic as default-ingest-handler. However having these workloads separated allows us to have specific configurations, considering the different loads of files manually ingested, and files ingested by the system. The
{pool}suffix refers to the process pool ID. - prepare-payload-{pool} : Once data is ingested, it often needs preparation. This workload consumes messages to prepare ingested files , frequently involving tasks like splitting large files into smaller, more manageable chunks for parallel processing. Then it transforms the prepared data and enriching it with critical business context relevant to your energy data. This is where the Market adapter and transformation configuration logic is applied.
- crunch-{pool} : These messages are consumed by the workload responsible for running triggered flows and complex computations. It handles demanding analytical tasks, aggregating data, calculating metrics, and executing intricate algorithms to derive deeper insights from your energy data.
A Quick Note: While these are some of our primary processing resources, our platform utilizes others, such as collective-trigger(for collective trigger logic), for other specific logics. We've focused on the main ones here for clarity.
Writer Workloads: Persisting Processed Data
As data is processed and enriched, messages containing various types of information (such as datasource, tags, timeseries, and audit event data) are sent to our writer workloads. These workloads are responsible for persistently storing data in our robust data warehouses: Google BigQuery (BQ) and Google Bigtable (BT). This ensures your data is readily available for reporting, analysis, and application consumption. These workloads consume specific data streams destined for storage.
- BigQuery (BQ) Writers (e.g.,resource-sink-bigquery-{pool}) : These workloads consume messages to store data in BigQuery. BigQuery is a highly scalable, serverless data warehouse optimized for large-scale analytical queries, making your processed data available for complex reporting and business intelligence.
- Bigtable (BT) Writers (e.g.,resource-sink-bigtable-{pool}) : These workloads consume messages to store data in Bigtable. Bigtable is a wide-column NoSQL database ideal for high-throughput, low-latency access to large datasets, particularly useful for time-series and operational data.
How Our Main Workloads Connect
The diagram below illustrates the typical flow of data and the relationships between the main processing and writer workloads described above: